1. 테이블 설계
분산 데이터베이스를 가정하여 아래와 같이 테이블을 설계하였다.
- N개의 샤드
- Shard Key : board_id(게시판 ID)

샤드키를 게시판 ID로 잡은 이유는 게시글은 게시판 단위로 조회되기 때문이다. 예를 들어, 개발 게시판에서는 개발 게시글을, 유머 게시판에서는 유머 게시글이 조회되어야 한다.

article_id를 샤드 키로 설정하면, 동일한 게시판에 작성된 게시글이 서로 다른 샤드에 저장될 수 있어 모든 샤드를 조회해야 한다. 샤드가 N개인 경우, 게시글 목록을 조회하기 위해 N개의 쿼리를 실행하고 목록을 병합하는 복잡한 처리가 필요하다. 이러한 서비스 특성에 따라 board_id를 샤드 키로 선정하면, 각 게시판의 게시글 목록 조회 시 단일한 샤드에서만 요청이 가능하다.
2. 게시물 조회에서 페이징이 필요한 이유
대규모 데이터에서 게시글 목록 조회 시 메모리, 네트워크, 성능 등의 제약으로 모든 데이터를 보여줄 수 없어 페이징이 필요하다.
페이징 처리 시 아래와 같은 이유로 모든 데이터를 메모리로 가져와, 특정 페이지만 추출할 수 없다.
- 메모리 부족(OOM): 전체 데이터를 메모리에 올릴 수 없어 시스템이 중단될 수 있음
- 디스크 I/O 부담: 디스크 접근은 메모리 접근보다 느려서 성능 저하 발생
따라서 특정 페이지의 데이터만 추출하는 페이징 쿼리를 사용해야 한다. 페이징 방식은 클라이언트 또는 서비스 특성에 따라 2개로 나눌 수 있다.
- 페이지 번호
- 이동할 페이지 번호가 명시적으로 지정
- 원하는 페이지로 즉시 이동 가능
- 무한 스크롤
- 스크롤을 내리면 다음 데이터가 조회
- 주로 모바일 환경에서 사용
3. 게시글 목록 조회 - 페이지 번호
페이지 번호 방식에서 두 가지 정보가 필요하다.
- N번 페이지에서 M개의 게시글
- 게시글 개수
1200만건 데이터엣에서 1번 게시판, 4번 페이지에서 30건 데이터 조회해보면 13초가 소요된다.
(article_id가 primary key이기 때문에 article_id 로 정렬해도 되지만, 설명을 위해 created_at 으로 정렬)

실행계획을 살펴보면

- type=ALL
- 테이블 전체를 읽는다. (풀스캔)
- Extra=Using where; Using filesort
- Using where : where절로 조건에 대해 필터링
- Using filesort: 데이터가 많기 때문에 메모리에서 정렬을 수행할 수 없어서, 파일(디스크)에서 데이터를 정렬하는 filesort 수행
전체 데이터(type=ALL)에 대해 필터링 및 정렬하기 때문에 아주 큰 비용이 든 것이다. 이러한 문제를 해결하려면 인덱스를 활용해야 한다.
3.1. 인덱스에 대한 이해
인덱스란?
- 데이터를 빠르게 찾기 위한 방법이다.
- 인덱스를 관리하기 위해서는 부가적인 쓰기 작업과 저장 공간이 필요하다.
관계형 데이터베이스에서의 인덱스 구조
- 관계형 데이터베이스에서는 주로 B+ Tree(Balanced Tree) 구조를 사용한다.
- 데이터가 정렬된 상태로 저장된다.
- 검색, 삽입, 삭제 연산을 로그 시간(log N)에 수행할 수 있다.
- 트리 구조에서 Leaf Node 간 연결이 되어 있어 범위 검색에 효율적이다.
인덱스를 추가하면?
- 쓰기 시점에 B+ Tree 구조의 정렬된 상태의 데이터가 생성된다.
- 이미 인덱스로 지정된 컬럼은 정렬된 상태를 유지하고 있기 때문에,
- 조회 시점에 전체 데이터를 다시 정렬하거나 필터링할 필요가 없다.
- 따라서 조회 쿼리를 더 빠르게 수행할 수 있다.
create index idx_board_id_article_id
on article(board_id asc, article_id desc);- article_id는 snowflake를 사용하여 시간 기반 오름차순 숫자 생성.
- 동일한 시간에 동시에 게시글 생성 요청이 들어와 created_at가 중복될 수 있으므로, created_at 이 아닌 article_id로 인덱스 생성
목록 조회의 최신순 정렬 조건을 article_id로 사용하면 쿼리문을 아래와 같이 작성할 수 있다.
SELECT *
FROM article
WHERE board_id = {board_id}
ORDER BY article_id DESC
LIMIT {limit} OFFSET {offset};
인덱스 데이터로 쿼리문이 수행되는 과정을 살펴보면
SELECT *
FROM article
WHERE board_id = 2
ORDER BY article_Id DESC
LIMIT 2 OFFSET 2;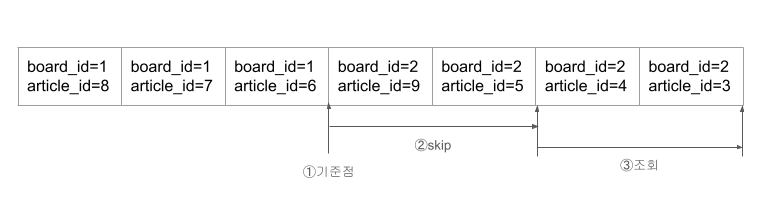
- where board_id = 2 필터링을 위한 기준점을 먼저 찾는다. 인덱스의 트리 구조에서 로그 시간에 찾을 수 있다.
- 인덱스를 스캔하면서 offset = 2까지 스킵한다. 2차 정렬 조건 article_id에 의해, 동일 게시판 내의 게시글 목록은 최신순 정렬되어 있다.
- 2개의 데이터를 조회한다. (limit = 2)
조회 시점에 데이터를 정렬하고 모든 데이터에 대해 직접 필터링하는 과정이 사라졌다.
데이터베이스에서 4번 페이지의 30개의 게시글을 다시 조회해보면, 13초 소요됐던 쿼리문이 0.005초에 수행되었다.

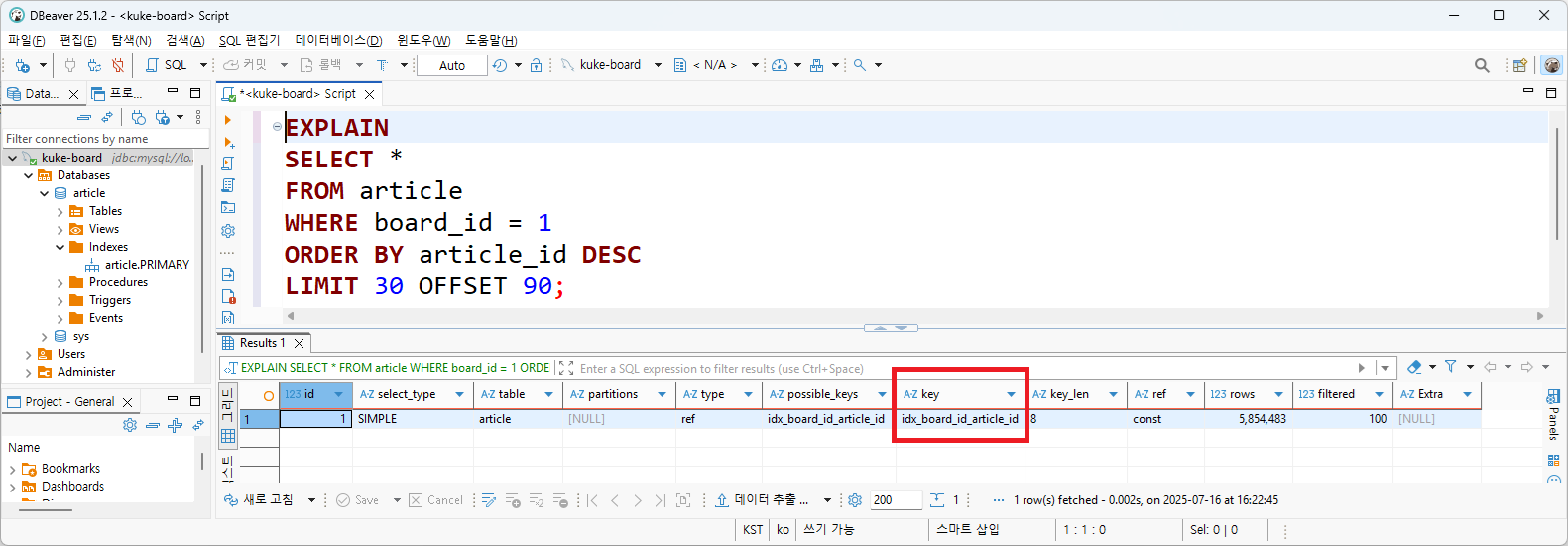
실행계획을 살펴보면
- key=idx_board_id_article_id
- 생성한 인덱스가 쿼리에 사용됐다는 것을 확인할 수 있다.
하지만 조회하는 페이지가 늘어나면 조회 속도가 느려지는 것을 확인할 수 있다. 50000 페이지를 조회해보면 게시글 30개를 조회하는데 6.5초가 소요됐다. 실행계획을 살펴봐도 동일한 인덱스가 사용되는 것을 확인할 수 있다.


offset 변경만 했을 뿐인데 성능이 느려진 이유를 알기 위해서는 인덱스의 종류를 알아볼 필요가 있다.
- Clustered Index
- Secondary Index
MySQL 기본 스토리지 엔진: InnoDB
스토리지 엔진(Storage Engine)이란?
- 데이터베이스에서 데이터를 저장하고 관리하는 역할을 담당하는 구성 요소이다.
InnoDB의 특징
- MySQL의 기본 스토리지 엔진이다.
- 테이블마다 Clustered Index를 자동으로 생성한다.
Clustered Index
- 테이블의 데이터가 인덱스 키 순서대로 물리적으로 저장되도록 만드는 인덱스이다.
- 인덱스의 리프 노드가 실제 데이터 행을 포함한다.
- 따라서 인덱스 자체가 테이블이라고 볼 수 있다.
- 테이블당 하나만 생성 가능하다.
- 이 인덱스가 데이터의 저장 순서를 결정한다.
- 일반적으로 Primary Key가 Clustered Index로 자동 생성된다.
- 필요한 경우, 다른 컬럼을 Clustered Index로 지정할 수도 있다.

테이블에 primary key (clustered index)를 정렬 기준으로 하는 인덱스가 자동으로 생성된다. leaf node에는 행 데이터(row data)를 가지고 있다.
article 테이블에는 article_id를 기준으로 하는 Clustered Index가 생성되어 있고, 데이터를 가진다. primary key를 이용한 조회는, 자동으로 생성된 clustered index로 수행되는 것이다.

article_id를 이용해서 임의의 게시글을 조회하면 primary key에 자동으로 생성된 clustered index가 사용된 것을 확인할 수 있다.
우리가 생성한 인덱스는?
- Secondary Index(보조 인덱스)로 Non-clustered Index라고도 불린다.
- Secondary Index의 leaf node는 다음 데이터를 가지고 있다.
- 인덱스 컬럼 데이터
- 데이터에 접근하기 위한 포인터
- 데이터를 가지고 있는 Clustered Index에 접근하기 위한 포인터.
- 일반적으로 Primary key
Secondary Index는 인덱스로 지정한 컬럼을 key로 가진다. 그리고 leaf node의 데이터는 인덱스 컬럼 데이터, 데이터에 접근하기 위한 포인터(PK)를 가진다. 여기에 board_id와 article을 애입해보면, article_id는 인덱스 컬럼 데이터이면서 데이터에 접근하기 위한 포인터이다.

Secondary Index는 데이터에 접근하기 위한 포인터(Clustered Index)만 가지고 있고, Clustered Index에 데이터가 존재하기 때문에 Secondary Index를 통해 Clustered Index에 접근 후 실제 데이터에 접근하게 된다.
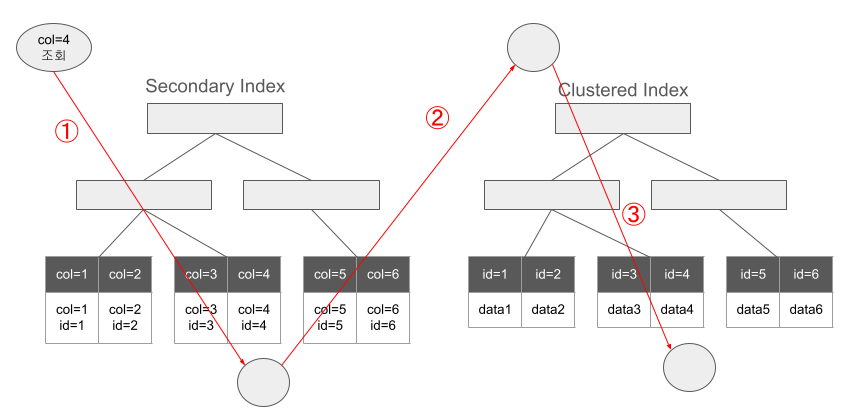
- Secondary Index를 조회하면 데이터에 접근할 수 있는 포인터(id)를 찾는다.
- Secondary Index에서 찾은 포인터 id로 Clustered Index에 접근한다.
- Clustered Index의 데이터에 접근해서 테이블 데이터를 읽는다.
즉 Secondary Index를 이용한 데이터 조회는 인덱스 트리를 두번 타게 된다.
- Secondary Index에서 데이터 접근을 위한 포인터를 찾은 뒤
- Clustered Index에서 데이터를 찾는다.
이 개념을 적용해서 페이징 쿼리를 분석해보면
SELECT *
FROM article
WHERE board_id = 1
ORDER BY article_id DESC
LIMIT 30 OFFSET 1499970;
- (board_id, article_id)로 생성된 Secondary Index에서 article_id를 찾는다.
- Clustered Index에서 article 데이터를 찾는다.
- offset 1499970을 만날 때까지 반복하며 skip한다.
- limit 30개를 추출한다
이와 같이 페이징 쿼리를 실행하면 아래와 같은 방식으로 데이터가 조회된다.

- (board_id, article_id) 로 생성된 secondary index에서 cluster index인 article_id를 찾아 데이터를 조회한다.
- 다음 offset으로 넘어가 같은 방식으로 secondary index에서 cluster index인 article_id를 찾아 데이터를 조회한다.
- offset 1499970을 만날 때까지 반복하며 skip 한다.
- offset1499970부터 30개의 데이터를 추출한다.
데이터는 offset 1499970부터 30개만 필요한데, offset 149970을 만날 때까지 데이터에 접근하고 있다. 즉, 불필요한 데이터 접근으로 인해 쿼리 속도가 느려진다.(1~3과정)
(board_id, article_id) secondary index는 board_id와 article_id를 포함한다. article_id는 secondary index에서 가져올 수 있는 정보이기 때문에, secondary index에서 필요한 30건에 대한 article_id만 먼저 추출하고 그 30건에 대해서만 clustered index에서 데이터를 가져올 수 있다.

전체 데이터 조회 시 6초 소요됐는데, board_id와 article_id만 조회하는데는 0.2초가 걸렸다.
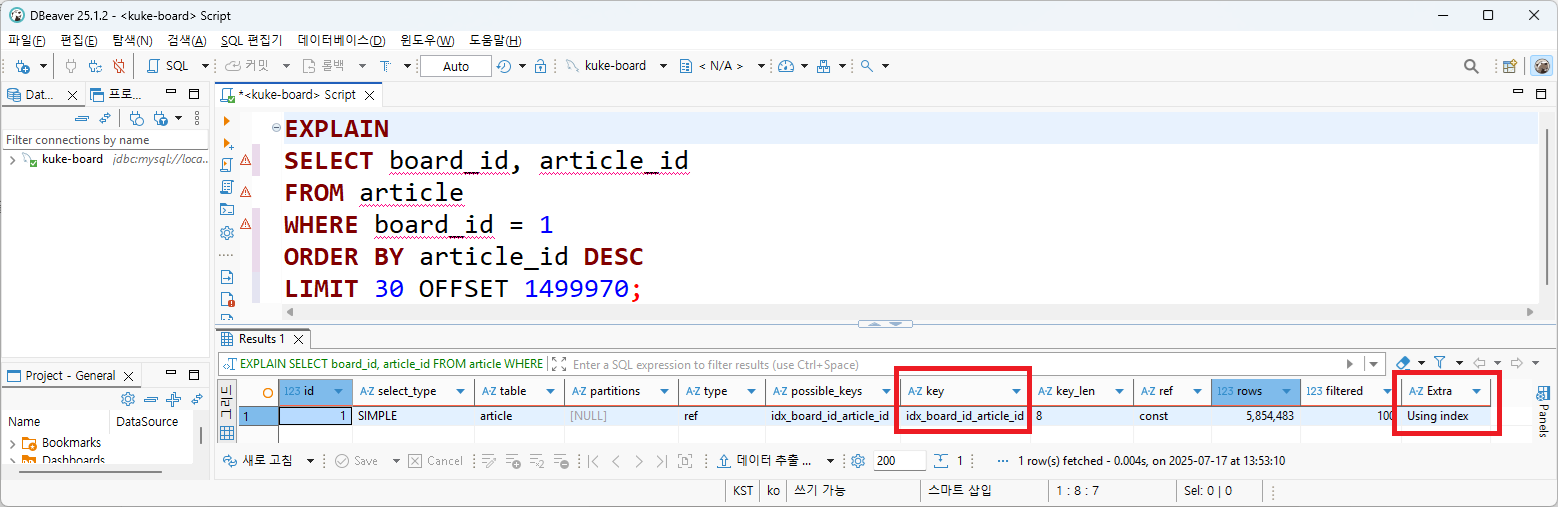
실행계획을 살펴보면
- key=idx_board_id_article_id 로 인덱스는 동일하게 사용됐는데
- Extra=Using index가 추가되었다. 인덱스만 사용해서 데이터를 조회했음을 의미한다.
인덱스의 데이터만으로 조회를 수행할 수 있는 인덱스를 Convering Index라고 한다.
Covering Index
- 인덱스만으로 쿼리의 모든 데이터를 처리할 수 있는 인덱스
- 데이터(Clustered Index)를 읽지 않고, 인덱스(Covering Index)에 포함된 정보만으로 쿼리 가능한 인덱스
SELECT board_id, article_id
FROM article
WHERE board_id = 1
ORDER BY article_id DESC
LIMIT 30 OFFSET 1499970;

위의 쿼리문은 Clustered Index에 접근하는 과정 없이 Covering Index를 활용하여, Secondary Index에서만 board_id와 article_id를 추출한 것이다.
추출된 30건의 article_id에 대해서만 Clustered Index에 접근하면 된다. 30건의 article_id를 서브 쿼리 결과로 만들고, article 테이블과 join하면 0.119초에 데이터가 조회되었다. 실행 계획을 살펴보면 article_id 추출을 위한 sub query에서 파생 테이블이 생기지만(DERIVE), 이 과정에서 커버링 인덱스가 사용되었다. 작은 규모의 파생 테이블과 join하여 30건에 대해서만 clustered index(PK)에서 데이터를 가져오기 때문에 빠르게 조회가 빠르게 처리될 수 있었다.
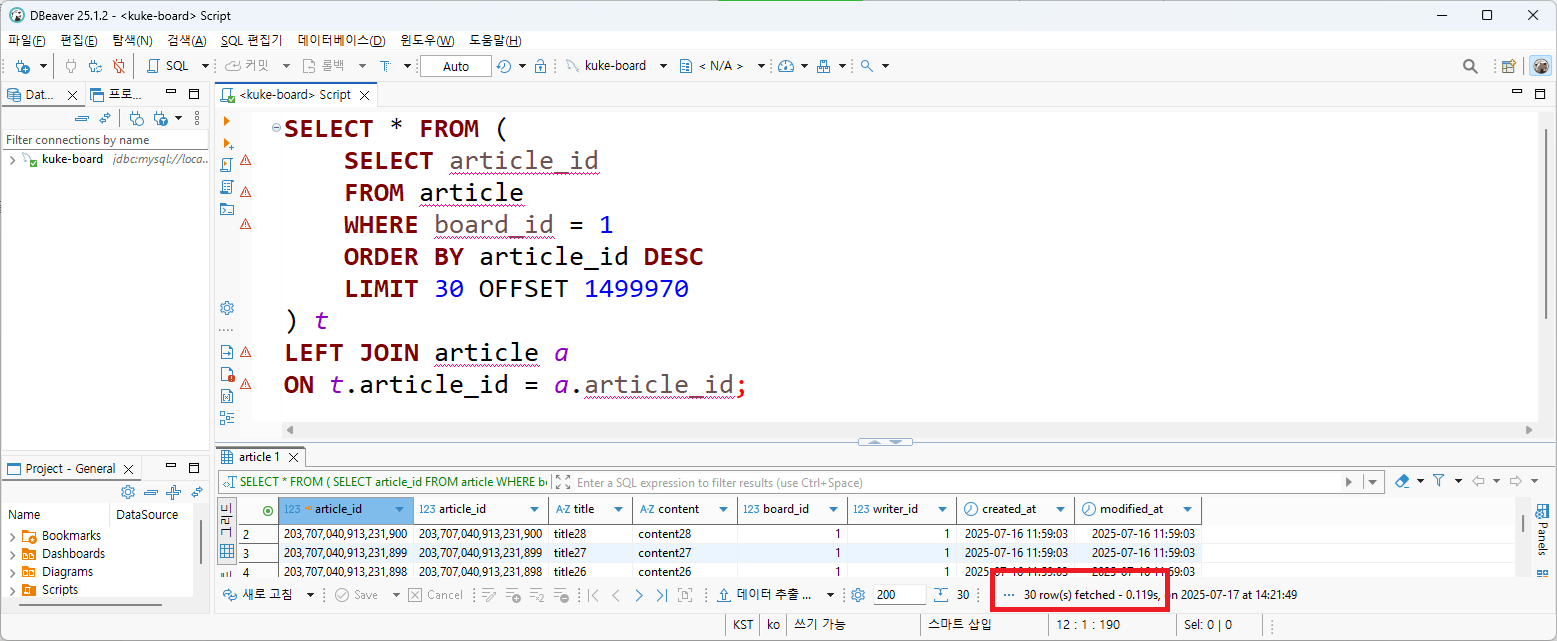
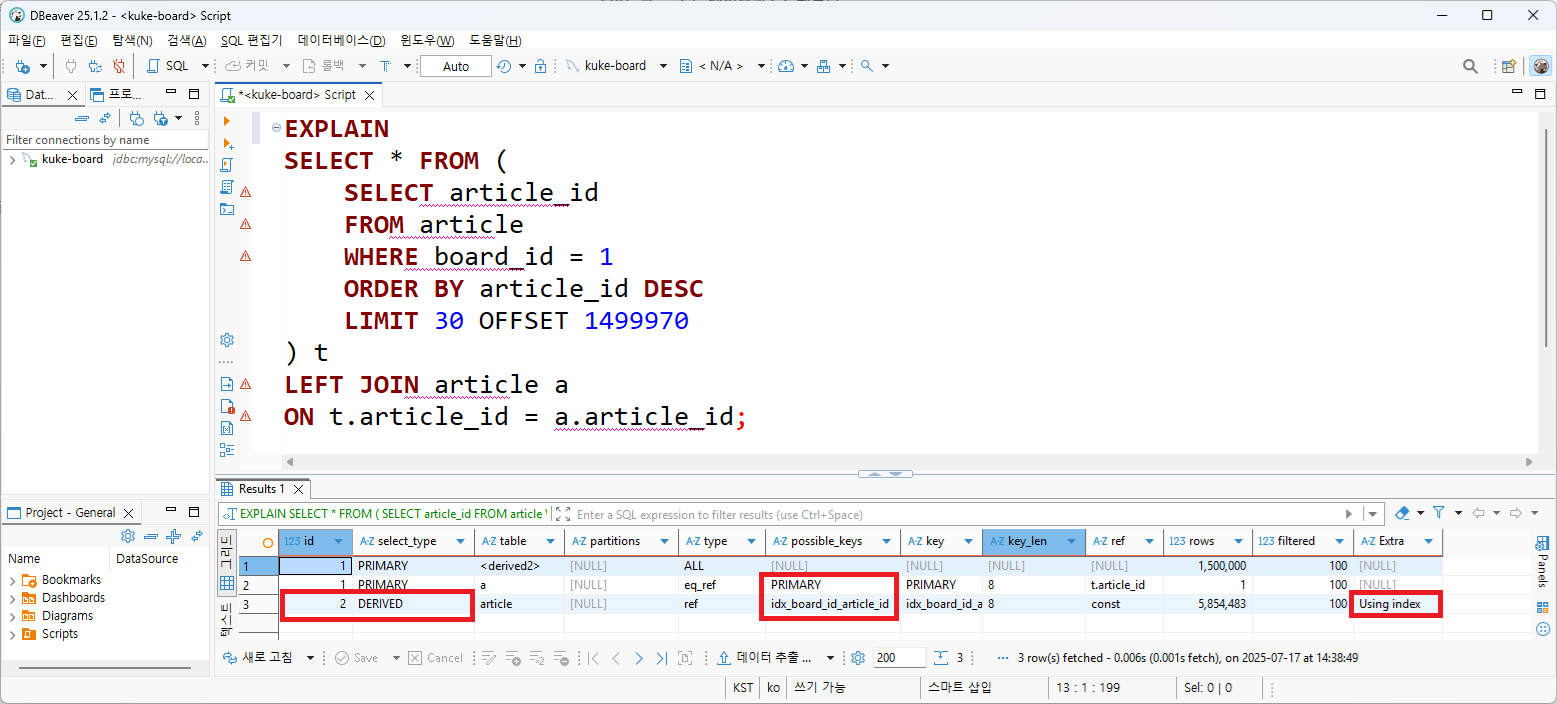
300000번 페이지를 조회하면 어떻게 될까? 동일한 쿼리문에 offset만 변경했는데, 데이터 조회에 1.5초가 소요되었다. 실행계획도 동일하다.


article_id 추출을 위해 secondary index만 탄다 하더라도, offset 만큼 index scan이 필요하다. 데이터에 접근하지 않더라도 offset이 늘어날수록 데이터 조회도 느려진다.

offset이 늘어날수록 느려지는 문제를 해결할 수 있는 방법으로는 무엇이 있을까?
- 데이터를 한번 더 분리한다.
- 게시글을 1년 단위로 테이블 분리 → 테이블을 작게해서 테이블에서 관리하는 데이터 개수 제한
- offset을 인덱스 페이지 단위skip하는 것이 아니라, 1년 동안 작성된 게시글 수 단위로 즉시 skip
- 해당 개수만큼 즉시 skip
- 더 큰 단위로 skip을 수행하게 되는 것
- 정책으로 풀어내기
- 300000번 페이지를 조회하는게 정상적인 사용자일까? → 10000번 페이지까지 조회 제한
- 시간 범위 또는 텍스트 검색 기능 제공 → 작은 데이터 집합 내에서 페이징 수행
- 무한스크롤
- 무한 스크롤에서는 뒷페이지로 가더라도 균등한 조회 속도를 가질 수 있다.
3.2. 페이지 번호
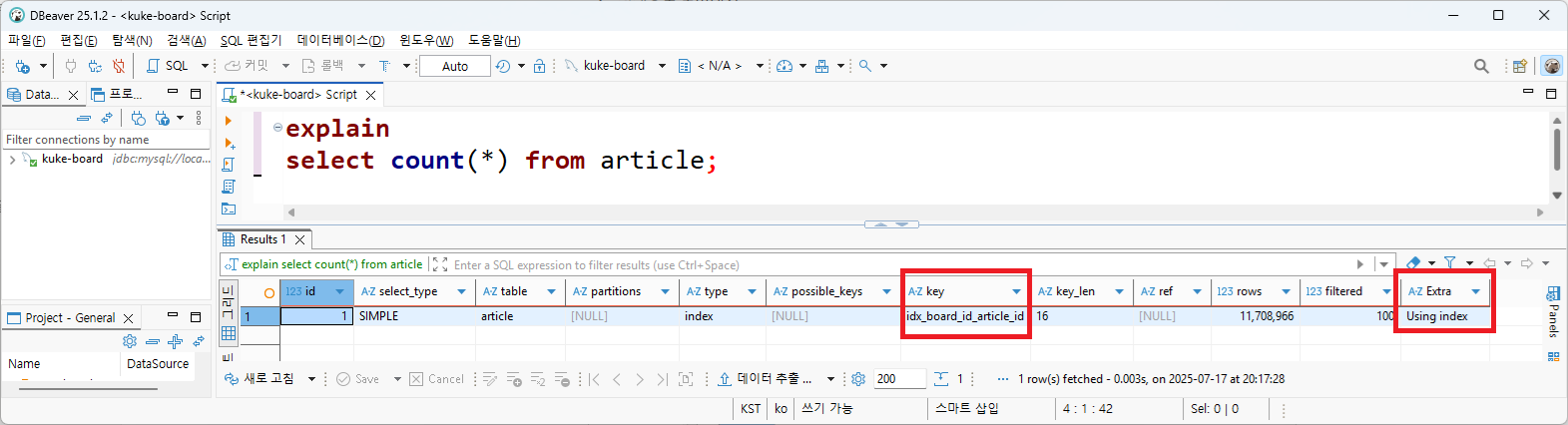
페이지 번호 방식에서는 게시글의 개수도 필요하다. 게시글 개수는 데이터 유무에 따라 페이지 버튼 활성화에 필요하다. 게시글의 개수는 count 쿼리를 수행하면 쉽게 알 수 있다. 인덱스를 사용하고, 개수만 카운팅하면 되므로 커버링 인덱스로 동작했다. 하지만 모든 데이터 수를 확인하므로, 실행 시간이 1.11초나 소요됐다. 데이터가 더 쌓이면 카운팅 시간이 더 느려질 것이다.

그런데 버튼 활성화를 하는데 전체 데이터 수를 전부 알 필요는 없다. 예를 들어, 5페이지를 보고 있는데 101페이지 버튼 활성화 여부를 알 필요가 없다는 것이다. 즉 이동 가능한 페이지 번호 활성화를 위해 모든 게시글의 개수는 알 필요 없고, 사용자가 현재 이용 중인 페이지 기준에 따라서 게시글 개수의 일부만 확인하면 되는 것이다.
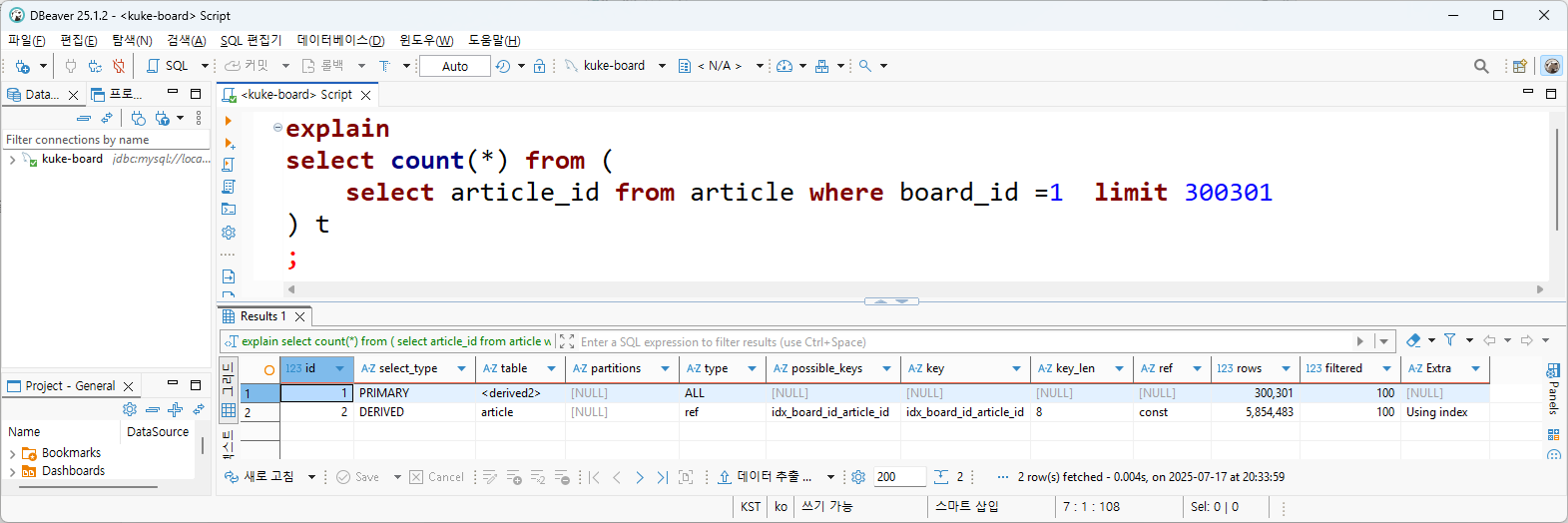
한 페이지에 30개씩 조회되는 게시판에서 사용자가 10001~10010번 페이지에 있다고 한다면, 300301개의 데이터만 데이터를 카운트하면된다. (마지막 1개는 다음 페이지 버튼 활성화에 필요.) 모든 게시글 개수를 카운트할 필요가 없으므로, 빠른 시간 내에 count쿼리가 수행된다. (0.084초)

[관련자료]
스프링부트로 직접 만들면서 배우는 대규모 시스템 설계 - 게시판| 쿠케 - 인프런 강의
현재 평점 4.9점 수강생 1059명인 강의를 만나보세요. 대규모 데이터와 트래픽을 지탱하기 위한 시스템을, 스프링부트로 직접 만들면서 배워봅니다. 대규모 시스템 디자인, Microservice Architecture, Eve
www.inflearn.com
'프로그래밍_인강' 카테고리의 다른 글
| 조회수 - InMemoryDB, 분산락 (1) | 2025.09.04 |
|---|---|
| 좋아요 수 설계 - 비정규화, 락 (0) | 2025.09.04 |
| Distributed Relational Database (1) | 2025.07.15 |